Apa Itu ICR
ICR adalah singkatan Intelligent Character Recognition, yaitu sistem ”cerdas” yang mampu mengenali tulisan tangan dan menterjemahkannya kedalam kode atau simbol digital yang ”dimengerti” (diedit, disimpan) oleh komputer. Sebuah piranti lunak ICR pada prinsipnya terdiri dari 4 bagian: preprocessing, character segmentation, character recognition dan post processing, sebagaimana ditampilkan pada Gambar 1 [1].

Gambar 1 Alur proses dalam sebuah sistem ICR
Dari sisi teknologi, sebenarnya ICR bukanlah hal yang baru. Riset mengenai character recognition telah berpuluh tahun digali di dunia komputasi, khususnya pattern recognition (pengenalan pola) dan image processing (pengolahan citra). Bagi peneliti pattern recognition, masalah character recognition seolah menjadi masalah klasik untuk mencoba berbagai metode feature extraction maupun classifier yang mereka kembangkan. Teknologi ini dapat dikatakan telah mencapai maturity, dimana umumnya penelitian telah dapat menekan rasio error hingga kurang dari 1% (akurasi 99%) [3][4]. Di sisi industri, teknologi ICR telah diimplementasikan dalam berbagai produk komersial. Misalnya untuk membaca alamat pos yang diimplementasikan di United States Postal Service (USPS) [5], Bank check recognition [6], dan facsimile produksi Sanyo yang mampu membaca tulisan tangan nomer facsimile, dan langsung men-dial secara otomatis ke tujuan [7]. Dapat dikatakan bahwa teknologi ini telah matang dan potensi aplikasinya sangat tinggi.
Tiap teknologi memiliki kelebihan dan kekurangan masing-masing. Kelebihan ICR terhadap berbagai metode lain dalam data entry seperti OMR (Optical Mark Recognition) misalnya, terletak pada kemampuannya
(i)mempermudah pekerjaan operator
(ii) efisiensi biaya kertas yang diperlukan
Mempermudah di sini dimaksudkan lebih mudah bagi seseorang untuk menuliskan sebuah angka dengan baik, dibandingkan mengisi form OMR dengan mencontreng atau menghitamkan sebuah pilihan dari berbagai pilihan yang tersedia, sebagaimana saat ujian nasional, UMPTN, dsb. Apalagi dengan mempertimbangkan stamina dan kondisi petugas lapangan yang mungkin dalam kondisi lelah saat mengisi formulir. Dari sisi efisiensi, biaya pengadaan kertas dapat ditekan jauh menjadi lebih murah. Pada pemilu kali ini, formulir C1-IT terdiri dari 8 lembar yang memuat isian untuk seluruh parpol. Apabila memakai formulir khusus OMR, banyaknya halaman akan sesuai dengan jumlah parpol, karena data 1 parpol memerlukan 1 halaman OMR. Misalnya jumlah parpol 38, maka diperlukan 38 halaman [8]. Namun demikian, bukan berarti ICR bebas resiko. Apabila akurasi ICR terlalu rendah, preprocessing dan segmentasinya tidak akurat, mengakibatkan beban operator untuk melakukan verifikasi menjadi berat, sehingga tidak efektif. Dapat disimpulkan bahwa dari sisi akurasi, OMR lebih menjanjikan daripada ICR, tetapi ICR lebih unggul dari sisi biaya pengadaan kertas maupun resiko error yang timbul karena kondisi psikis di lapangan.
Apakah yang harus dilakukan agar ICR bekerja optimal ?
Dari uraian di atas jelas terlihat bahwa ICR ini berada pada ujung tombak sistem TI yang digunakan. Keberhasilan tabulasi nasional sangat bergantung pada keberhasilan ICR dalam membaca data yang dituliskan pada formulir C1-IT. Mengingat pentingnya peran ICR dalam sistem TI Pemilu 2009, perangkat lunak itu harus memenuhi 4 aspek:
Selain itu dari sisi pengguna, harus diperhatikan hal-hal sbb.
Standarisasi ICR
Sejak dibentuk lewat MoU BPPT-KPU pada 12 Maret 2009, tim review BPPT berupaya membuat standar ICR, agar dapat diolah oleh bagian Sistem Integration, untuk dikirim, diolah dan ditampilkan pada tabulasi nasional [9]. Standar ICR ini merupakan penjabaran teknis dari spesifikasi yang ditetapkan pada Peraturan Komisi Pemilihan Umum No. 02 tahun 2009 [1]. Setiap vendor yang ingin menjual produk ICR nya harus memenuhi kriteria standar tersebut, agar hasilnya dapat diterima dan diolah oleh sistem yang dibangun di KPU.
Referensi
Intelligent Document Processing (IDP) adalah teknologi berbasi AI/ML yang dapat memproses dokumen dengan menggabungkan Pengenalan Karakter Optik (OCR) dan Natural Language Processing (NLP) untuk membaca dan memahami dokumen dan mengekstrak istilah atau kata tertentu.
VibiCloud dengan teknologi AWS menawarka cara yang sangat fleksibel untuk menerapkan Inteligent document processing berbasis AI/ML. Service yang digunakan diantaranya adalah :
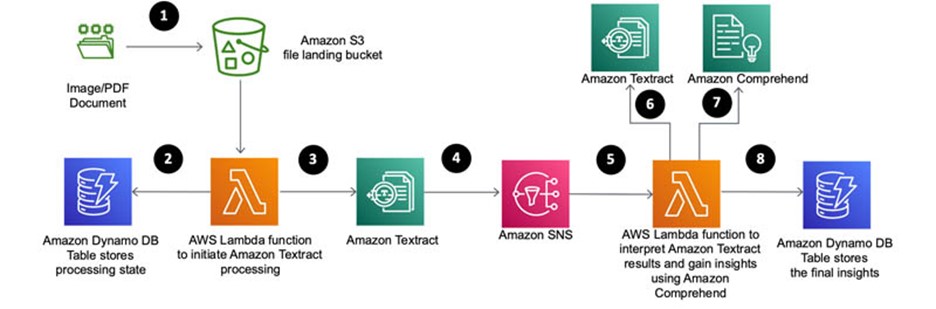
Intelligent Document Processing yang menggabungkan ketiga layanan AWS yang sudah dijabarkan diatas dapat memberikan cara yang andal untuk mengurangi biaya dan upaya manual seperti mencari dokumen yang dibutuhkan tanpa harus membuka file satu persatu, salah satu keunggulan nya cukup dengan mencari kata yang di butuhkan makan akan muncul kata tersebuth ada di dokumen yang mana. Semua itu akan dapat meningkatkan hasil bisnis perusahaan.

